Managing transactions in the cloud, Part 2: Meeting the challenges
In Part 1 of this series, you learned about transaction processing and distributed transactions. Transactional properties help to reduce the error-handling effort in an application. But we also found that distributed transactions, which manage transactions across multiple resources, are not necessarily available in cloud-based runtimes. Here in Part 2, we look at the cloud setup, and ways of ensuring transactional qualities across multiple resource managers even without distributed transactions.
Note: this article has originally been published on IBM's developerWorks website on 18. March 2017, and is here republished within IBM's publishing guidelines.
In a cloud setup, distributed transactions are frowned upon even more than in a classical setup. Resources (resource managers such as databases) can be volatile, as can transaction managers. They can be started or stopped at any time to adjust for different load situations. Restarting a resource manager aborts all transactions currently active in it, but what about transaction managers in the middle of the voting phase of a distributed transaction? Without the persistent transaction manager transaction log, transactions are lost in limbo and resources locked for those transactions will never be released by their resource managers.
Also in a cloud setup, as well as in some previous service-oriented architecture (SOA) setups, the protocols used to call a resource manager very often do not support transactions (such as REST over HTTP calls). With such a protocol, a call is equivalent to an autocommitted operation, as described in Part 1.
The cloud makes it easier to quickly deploy new versions or quickly scale your application, but it can be more difficult for the application programmer. Using what you have learned here about transaction management should help you create applications that work better in the cloud.
Therefore, while you could probably set up the application servers in the cloud with a shared, persistent transaction log on separate storage infrastructure to compensate for volatile operations, popular communication protocols that do not support transactions prevent the use of transactions.
This means that in a cloud setup you have to make do without distributed transactions. The following sections present a number of techniques to coordinate multiple resources in a non-transactional setup.
Ways to handle distributed transactions in the cloud
The underlying assumption to transaction processing is that you want multiple resources to be consistent with each other. A change in one resource should be consistent with a change in another resource. Without distributed transactions, these error-handling patterns can be used for multiple resources:
- A change is performed in only one of the resources. If this situation is acceptable from a functional point of view, transactions can be autocommitted, and the error situation in the other resource can be logged and ignored.
- The change in the first resource is rolled back when an error occurs, changing the second resource. This requires that the transaction on the first resource still be open when the error occurs, and is rolled back when the error occurs. A variation of this theme is when the transactions on both resources are kept open, and the error happens on the first commit of one of the two transactions. Here the rolled-back change in the first resource is not visible to the outside, so on rollback no window of inconsistency appears.
- One resource is changed. A change in the second resource to become consistent with the first resource is then performed at a later point in time. The reason could be a recoverable error situation changing the second resource, but it could also be an architectural pattern that defers the changes in the second resource anyway, such as in batch processing. This pattern creates a (larger) window of inconsistency, but in the end consistency is achieved eventually. The name of this pattern is thus "eventual consistency." I call this "roll-forward inconsistency" as the second change is committed.
- The change in the first resource is compensated when an error occurs, changing the second resource at a later time. For this pattern the first resource needs to provide a compensating transaction to roll back the changes in a separate transaction. This also creates eventual consistency, but the error pattern is different from the roll-forward inconsistency above. I call this a "roll-back inconsistency," as the first change is rolled back.
In the following section, I look at the techniques to employ the "eventual consistency" property. The system will not be immediately consistent, but it should become consistent a short time after the transaction is committed.
Mitigation techniques
How can error conditions be reduced so that errors won't happen frequently, or won't even happen at all?
Ignore—and fix later
The easiest approach, of course, is to ignore any error situation, and fix it up with a batch job later on. However, that is also not as easy as it seems. Consider a shop system with a shopping cart in one database and an order-processing service. If the order service is not available and you ignore it, you need to do the following:
- Keep a status on the shopping cart that the order has not been successfully been sent yet.
- Consider the time needed until the batch runs to fix the situation. If it is running at night only, you may lose a day until order processing in your backend, possibly creating dissatisfied customers.
Figure 1 shows an example of an eventual consistency batch fixing up inconsistencies.
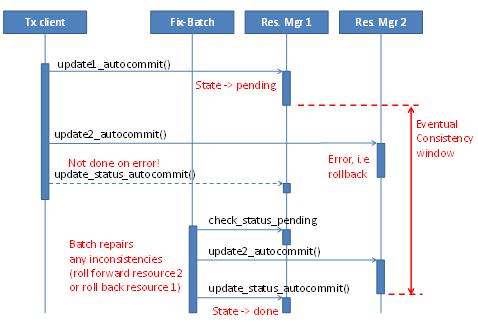
A variation of this theme is to write a "job" to the database, and have a background process continuously try to deliver the order until successful. In a sense, in that case you would be building your own transaction log and transaction manager.
Time-based pessimistic locking
Pessimistic locking is a technique that allows transactions to ensure the resource they want to change is actually available to them. Pessimistic locking prevents other transactions from modifying a resource (like a database row) and is sometimes even necessary in a short-lived technical transaction.
In a long-running business transaction as described in Part 1, a first short-running transaction changes the state of the resource so that other transactions cannot lock it again. In the credit card example discussed there, we saw that such techniques can successfully be used at scale in a long-running business transaction. But this technique also works in a cloud setup.
There is one caveat: You need to make sure that the lock is released when not needed anymore. You could do this by successfully committing a change on the object or rolling back the transaction. Basically you need to write and process a transaction log in the transaction client or transaction manager, to ensure the lock is released even after other possible errors have happened.
If you cannot guarantee that the lock will be released, you could use time-based pessimistic locking: a lock that releases itself after a given time interval as a last resort. Such a lock can be implemented with a simple timestamp on the resource, so no batch job is needed.
A lock introduces a shared state between the transaction client and the resource manager. The lock needs to be identified and associated with the transaction. You therefore need to pass either a lock identifier or a transaction identifier between the systems to resolve the lock on commit or rollback.
Compensation
Note that contrary to pessimistic locking, optimistic locking is not an error-avoiding technique: It is one to detect inconsistencies. While pessimistic locking reserves a resource for a transaction, a more optimistic approach is to assume that no inconsistency occurs and to directly perform the local change for a transaction in the first step. But then you need to be able to roll back the change in case the inconsistency does occur. This is a compensation of the optimistically performed operation.
In theory, this is a nice approach, as you need "only" to call the compensation service operation when the operation is rolled back. However, in a JEE application, for example, a resource manager can decide to roll back not when the change is performed, but also when commit() is attempted, as some database constraints may only be checked at commit time. The result is that you need to write your own Java resource adapter because only then do you know for sure whether a transaction on another resource has been rolled back or committed. But this introduces distributed transactions again, which we want to avoid in a cloud setup for the reasons mentioned above. Also, you have the question of what happens when your compensation fails for some reason.
A better approach is to note the failure in some kind of transaction log, for example, a row written to a specific table in a separate (autocommit transaction) operation. Then you let a batch job process the compensation at a later time. A problem, however, occurs when the second change is fully processed at the called service, but the caller does not receive a response, as shown in the next section. If the first resource is then compensated, you have generated another inconsistency. If such situations should be avoided, also check the state of the second resource before trying to compensate the first change.
As you can see here, discussing all the different possible error modes is a tedious but necessary endeavor. Only one more specific situation remains to be discussed: an operation actually succeeds, but the caller does not receive the reply and assumes an error.
Repeatability (idempotence)
Consider the shopping cart and the order service again. Assume the order service has been called, but only the reply has gone missing on the network. The caller does not know that the order service call succeeded and will try again. The order should not be processed twice of course, so what can be done?
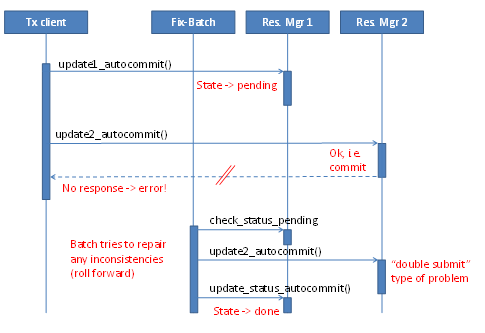
Figure 2 shows such a situation. The problem is similar to the "double submit" problem in web applications, whereby the accidental double-clicking of a button the same request is sent to the server twice. What if the server response resource manager detects this repeated call? In our example, the order service has to identify the second call as a repeated call and can return just a copy of the first call's result, and the actual order is processed only once; the order service is "repeatable."
Repeatability of a service helps greatly in reducing the complexity of error handling in a setup without distributed transactions. The actual meaning is that a service is idempotent: You can repeat a service call multiple times and the result will always be as if the service was called only once. But of course this should only happen to the very same order. Another order should be processed as a new order, possibly even one with the same content.
This solution could be implemented by comparing all attributes of a service call. My bank, for example, rejects a transaction with the identical amount, subject, and recipient, just in case I entered a transaction twice into the online banking application by accident.
More robustly, a transaction identifier sent with the request can help detect double submits. In that case, the called service operation registers a transaction ID sent by the caller and when the same ID is used again, it returns only the original result. But this may introduce a shared state (the transaction ID) between service instances in a cluster, so that a repeated call to another cluster member is still processed only once, thus creating another consistency problem.
Manual transaction and error handling
With the lack of distributed transactions, the system needs to look at each "operation" and decide how to tackle it in a way that ensures consistency. A client calling multiple resource managers—each possibly in its own transaction—must carefully decide which resource manager to commit first and what to do with the other in case of an error. This depends on the functional requirements. Non-transactional resources such as web services are even worse, because they cannot be rolled back but only compensated. What the resource manager used to do for us in a classical system we now have to do ourselves.
Consider this example from one of my projects. In this project, we stored some records in another system using a web service, which we needed to reference later. As the local transaction sometimes ran into an error, we had to seriously look at when the error occurred and where to call the compensating operation. In the end, we made the call repeatable and did away with the compensation altogether. If a transaction was rolled back, the next try would write (and overwrite) the same record again, and we had the pointer we needed for referral without any leftovers from previous tries.
In another example, we were forced to keep a reference counter of a master data record usage in another system, using an increment/decrement web service. Whenever we created an object referring to the master data record (that is, store its ID), we had to increment the counter, and decrement it when deleting the object. We had two problems with it. First, the call was a web service and we had to use a Java resource adapter to handle rollbacks. Even then, errors occurred even during rollback, for example, due to network problems. Secondly and worse, decrement was not a 100% compensation. If the value reached zero—for example in a rollback—there was the danger that the master data record would be deleted (which we were told only afterward, of course). In the end, we counted only up to when we created an object, and noted in a separate (transaction) log table whenever we did something with this master data record. A separate nightly batch then fixed the counter value.
Examples such as these are common. Even eBay uses a basically "transaction-free" design. At eBay, most database statements are auto-commit (which is similar to a web service call); only in certain, well-defined situations are statements combined into a single transaction (on that single database). Distributed transactions are not allowed. (See "Scalability Best Practices: Lessons from eBay.")
Related work
In a related scenario for distributed replicated databases, a new "BASE" paradigm has been introduced:
- Basically Available
- Soft state
- Eventual consistency
Availability is prioritized over strong consistency, which results in a "soft state" that may not be the latest value, but may be eventually updated. This principle applies to the database area, but is also relevant to web services or microservices deployed in the cloud.
The new eventual consistency paradigm can be even be acceptable in some functional scenarios. See, for example, Google's discussion at "Providing a Consistent User Experience and Leveraging the Eventual Consistency Model to Scale to Large Datasets."
Going further, one can try to find and use algorithms that are safe under eventual consistency. Recently, the "CALM theorem" was proposed. Basically, this theorem holds that some programs (those that are "monotonic") can be run safely on an eventually consistent basis. For example, adding a counter by using a read operation, adding 1, then writing it back is susceptible to consistency problems. Adding to a counter by calling an "increment" operation on it is not. See "Eventual Consistency Today: Limitations, Extensions, and Beyond" and "CALM: consistency as logical monotonicity" for more information.
Conclusion
Having to do without the strong consistency models guaranteed by distributed transactions makes the life of the average programmer much harder at first glance. Work previously done by the transaction manager must be done by the programmer, especially in the area of error handling. On the other hand, the programmer's life is also made easier: Programming for eventual consistency from the start makes the program much more scalable and more resilient to network delays and problems in a world that is much more distributed than his own datacenter. Not everyone creates applications for an eBay-like scale from the start, of course, but distributed transactions can create significant overhead. (I confess that I personally regret not being able to use at least one database and a message store in a single transaction, however.)
How does one cope without distributed transactions? In a new system, try to find algorithms that solve your business problem but work under eventual consistency (look at the CALM theorem). Challenge the business needs on strong consistency requirements. Make sure the services you call are adapted to this architecture by being repeatable (idempotent) or by providing proper compensations. In an existing system, modify your algorithms to make them simpler and less prone to failures in the services your system calls using techniques as described here.
The cloud makes it easier to quickly deploy new versions or quickly scale your application, but it can be more difficult for the application programmer. Using what you have learned here about transaction management should help you create applications that work better in the cloud.
Many thanks to my colleagues Sven Höfgen, Jens Fäustl, and Martin Kunz for reviewing and commenting on this series.