Managing transactions in the cloud, Part 1: Transaction basics and distributed transactions
As a customer buying an item in a web shop, you want to have the order quickly processed and delivered. As a bank customer, you want to make sure your money does not magically disappear during a transfer. In enterprise applications, classical transactions guarantee qualities such as consistency or isolation from other transactions. Distributed transactions provide such guarantees across multiple resources such as across your shop database and your enterprise resource planning (ERP) system. The transactional qualities are usually provided by your middleware infrastructure and make life easier for the average programmer.
In the cloud, however, the middleware often does not guarantee such qualities; distributed transactions are usually not available, while at the same time the infrastructure can be much more volatile.
In Part 1 of this two-part series, I describe some of the background of transaction processing, qualities guaranteed by transaction, and what is different in a cloud setup. In the second part, I will show alternatives to classical transaction processing for calling non-transactional services.
Note: this article has originally been published on IBM's developerWorks website on 18. March 2017, and is here republished within IBM's publishing guidelines.
A main attribute of a transaction is its Atomicity. In a real-world distributed transaction, this may not be fully achieved, and thus Consistency can be broken as well.
General properties of a transaction
In the IT world, a transaction is generally considered to be a separate operation on information, which must succeed or fail as a complete unit. A transaction can never be partially complete. This is an important property. All financial operations, for example, rely on transactions in a way that the total amount of money does not change: if you take money from one account, you make sure the money is put into another account at the same time.
More formally, transactions are often associated with the four "ACID" properties:
- A = Atomicity. A transaction can only be "all or nothing." Either on success, all operations in a transaction are performed, or on failure, none of the operations is performed.
- C = Consistency. A transaction will bring the system from one consistent state to another consistent state. Any data written to a database must, for example, obey all the constraints defined in the database (on commit).
- I = Isolation. Multiple concurrent transactions are isolated from each other in that they behave as if they were executed sequentially.
- D = Durability. Once a transaction is committed, the result of the transaction is there to stay, even in case of power losses or other errors.
While these are the theoretical principles of a transaction, in the real world there are effects and optimizations that bend those principles for the sake of performance.
For example, while Atomicity, Consistency, and Durability are strong goals in a transaction-processing system, Isolation is often more relaxed due to possible performance impacts of a strict isolation. Different transaction isolation levels have been defined to determine which isolation failures are allowed in a system. These isolation levels appear within a single database, so we will not focus on that subject here.
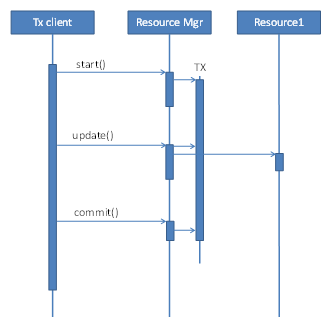
A transaction is usually initiated by a transaction client, calling a resource manager, very often a database or a message queue. The resource manager manages resources such as database tables and rows in a database. The client opens a transaction, and, in possibly multiple calls, performs a number of operations on one or more resources in the system, before it tries to commit the transaction. See Figure 1. With a single resource manager in a transaction, the resource manager can for itself decide whether a transaction is correct in the terms of Atomicity and Consistency and can, on commit, ensure Durability.
Autocommit
The discussion above uses explicit transaction demarcation with the start() and commit() operations, so multiple operations on a resource can be grouped into a single atomic change. During the transaction, the affected resources are locked against other changes. The decision whether to commit or roll back can then also depend on the outcome of other actions and possibly on other resources.
When a transaction client wants only to perform a single operation on a resource, there is no need to involve multiple calls to a resource manager. A single change on a single resource can be "autocommitted," that is, become effective immediately, as shown in Figure 2.
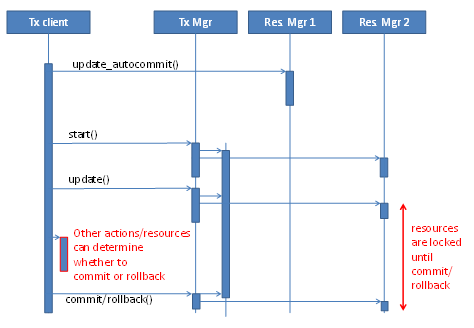
The decision whether to autocommit or use explicit commit or rollback for a single resource also plays a role in the error-handling patterns used for changes in multiple resources as described below.
Long-lived versus short-lived transactions
The properties of a transaction as given above are valid for a transaction in the general sense. For example, even for a business transaction like a purchase with a credit card, you want those properties to hold. Some transactions, however, may take a long time. For example, when you check in to a hotel, the hotel usually inquires electronically whether your account has enough money (that is, the limit on the card). However the charge to the account is not made until perhaps days later when you check out. Such transactions are called long-running transactions. These are business transactions that are typically broken up into multiple technical transactions, to avoid blocking (technical) resources in the transaction and resource managers.
Note that resource managers usually don't provide facilities to lock resources across technical transactions. For a long-running business transaction to be able to lock a resource, usually the functional data model needs to be adapted to store this extra state of the resource.
For example, on check-in to the hotel, a short-lived technical transaction reserves some amount on your account. The state of the reservation stored can be stored in a separate row in the database, and on reservation it is confirmed that the combined reservation doesn't exceed your limit. On check-out, another short-lived technical transaction then exchanges the reservation with the actual money transfer. Each technical transaction may (within the limits of the isolation levels mentioned above) fulfill the ACID properties, but the business transaction does not. The reserved money is not isolated from other transactions as it cannot be reserved by other business transactions.
To ensure Atomicity and Consistency in long-running business transactions, special techniques can be used. Reserving money for a credit card transaction basically is a form of pessimistic locking, for example. We will discuss such techniques in more detail later, for a cloud setting.
(For more discussion on this subject, see "Web-Services Transactions" at the SYS-CON Media website.)
Local versus distributed transactions
A local transaction involves only a single resource manager. But what happens when you need to involve two or more resource managers in a transaction? This happens when you have to manage data in two databases, or send a message in a message queue depending on some state in the database. In such cases, just committing the first resource manager and then the second one does not work. If the second resource manager rolls back due to some constraint violations, how do you roll back the first resource manager if it is part of the transaction that is already committed?
The usual approach, and one that has been used very successfully, is to use a transaction manager coordinating the resource managers involved in a transaction. The transaction manager then uses a distributed transaction protocol, usually "two-phase-commit," to commit the transaction.
In two-phase-commit, the transaction manager first asks all participating resource managers to guarantee that the transaction will succeed if committed. This is the "voting phase." If all resource managers agree, the transaction will be committed to all resource managers in the "commit phase." If even one resource manager rejects the commit, all resource managers will be rolled back and consistency is guaranteed. Figure 3 shows a two-phase-commit transaction.
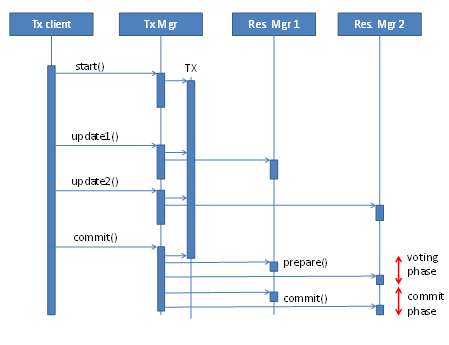
This model is successfully used in such systems as host-based transactions processing, Enterprise Java (JEE) application servers, and the Microsoft Transaction Server. (See "A Detailed Comparison of Enterprise JavaBeans (EJB) & The Microsoft Transaction Server (MTS) Models.")
Note that distributed transactions are not restricted to application servers but are also available for web services. There is a "WS-Transaction" standard for web services, but I have not yet seen it in actual use.
Distributed transactions in the real world
A main attribute of a transaction is its Atomicity. In a real-world distributed transaction, this may not be fully achieved, and thus Consistency can be broken as well. Consider a two-phase-commit transaction between a message queue and a database. A state is written to the database, and a related message is sent to the queue. Considering Atomicity and Consistency, one would expect that once a message is received from the queue, the database state is consistent with it. This is the strong consistency model guaranteed by classical transactions. However, as the commit that is sent from the transaction manager to the two resource managers is sent one after the other, the change in the first resource might be seen before the change in the second resource. For example, a database as second resource may take more time to do the actual commit, and the message committed to the first resource manager could have already been received. Processing therefore fails as the database state is not yet seen. This does not happen often, but it does happen occasionally, and I have experienced it personally. (See "Two-phase commit race condition on WebLogic" and "Messaging/Database race conditions.")Therefore, even in classical distributed transactions, there is a "window of inconsistency" where transactions are only eventually consistent. See Figure 4.
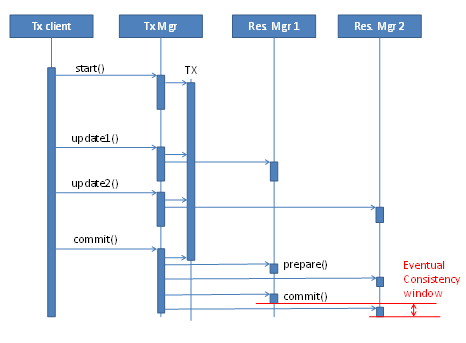
Another point is that the two-phase-commit protocol requires that both phases are performed completely to release any blocked resources, such as database records. To ensure completeness of the transaction even in the case, for example, of transaction manager outages or restarts, the transaction manager itself writes its own transaction log that is kept when it is stopped. This log is then read when the transaction manager starts and pending transactions are completed. A persistent transaction log, usually written to the file system, thus is a requirement for supporting two-phase-commit transactions in a transaction manager.
A two-phase-commit transaction requires multiple remote calls just for the commit operation. Due to this perceived overhead of distributed transactions, even in a classical JEE setup these calls are often avoided. However, they can be used when needed to ensure consistency across resource managers.
Transactional Asynchronous (Messaging) Protocol)
One specific case where a distributed transaction is really well invested is when coupling message-oriented middleware with a database transaction. Making sure a message is taken out of a queue only when the database transaction succeeds is a very nice feature and reduces error-handling effort in the application. Making sure a message is sent only when the database transaction can be successfully committed also helps providing consistency between databases and messaging queues.
In such a setup, the distributed transaction is restricted to the "local" database and a messaging server, and does not include other resource managers. The messaging system then ensures the transactional properties between the sending and receiving application servers. This approach is eventually consistent, as the receiving resource is changed only after the point where the change in the sending resource is committed.
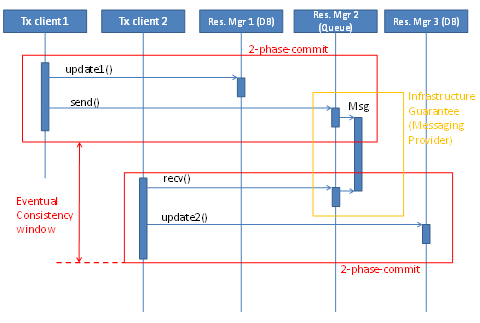
Using message-oriented middleware, an event-driven architecture with transactional qualities can be created, and much of the error handling can be delegated to the transaction managers.
Conclusion
In this part, I have discussed transaction basics as well as distributed transactions. Due to their properties, transactions can make error handling easy, not only with a single resource but especially across resources. We learned how two-phase-commit distributed transactions work and that even they are only "eventually consistent," if only by a small time interval. We also learned that a persistent transaction log in the transaction manager is a requirement for distributed transactions.
In many cloud deployments (CloudFoundry, for example), no persistent file system is available. A JEE application server runtime therefore cannot write its own transaction manager transaction log, because no two-phase-commit transactions are available. Also, in some of the new runtime environments, such as a JavaScript server, runtimes do not even have a transaction manager available at all. (See "Microservices Best Practices for Java.")
In Part 2 of this series, we will look at alternatives to distributed transactions that still provide some of the transactional guarantees. Using these alternatives you can ensure transactional qualities even in a cloud application, and make sure the orders in your web shop are processed correctly.